Falcon LLM: A New Standard in Language Learning Models
Artificial Intelligence (AI) and Natural Language Processing (NLP) have transformed our interactions with technology. Language Learning Models (LLMs) are one such innovation at the forefront of this transformation. Today, we introduce the Falcon LLM, an AI assistant that harnesses the power of the Hugging Face's Transformers library to provide helpful, detailed, and polite answers to user's questions.
The Falcon Large Language Model (LLM), as presented, is a significant advancement in the field of LLMs. It has been positioned as a game-changer, dethroning the previously top-ranked LLaMA on the Open LLM Leaderboard maintained by HuggingFace. The model's architecture and training process are well-detailed, highlighting its efficiency and the fact that it significantly outperforms GPT-3 while requiring less computational resources.
Falcon LLM's unique features, such as its custom tooling and unique data pipeline, are well-highlighted. The model was trained on one trillion tokens, a process that required 384 GPUs on AWS over two months. The team at the Technology Innovation Institute, who developed Falcon LLM, focused on data quality at scale, given that LLMs are highly sensitive to the quality of training data. They built a data pipeline that scaled to tens of thousands of CPU cores for fast processing and was able to extract high-quality content from the web using extensive filtering and deduplication.
However, while the model's capabilities and technical aspects are well-presented, there seems to be a lack of discussion on potential limitations or challenges associated with Falcon LLM's implementation. It would be beneficial to have a more balanced perspective, including potential drawbacks or areas for improvement.
Falcon LLM & Streamlit implementation
The Falcon LLM is a Python-based application which integrates Hugging Face's state-of-the-art language models and the intuitive interface of the Streamlit library to create a user-friendly AI assistant. Let's delve a bit deeper into the Python code that drives the Falcon LLM.
import streamlit as st
from langchain import HuggingFaceHub
from langchain import PromptTemplate, LLMChain
import os
# Set Hugging Face Hub API token
os.environ["HUGGINGFACEHUB_API_TOKEN"] = 'Enter your key here'
We start by importing the necessary libraries. Streamlit is a framework for building machine learning and data science web applications, while HuggingFaceHub, PromptTemplate, and LLMChain are from langchain, a utility library to work with Language Learning Models (LLMs) and Hugging Face models.
Next, we set our Hugging Face Hub API token as an environment variable. This token allows us to use Hugging Face's repository of pre-trained models.
# Set up the language model using the Hugging Face Hub repository
repo_id = "tiiuae/falcon-7b-instruct"
llm = HuggingFaceHub(repo_id=repo_id, model_kwargs={"temperature": 0.3, "max_new_tokens": 2000})
In this snippet, we specify the repository ID of our model hosted on Hugging Face's Model Hub. We then instantiate the HuggingFaceHub class with our repository ID and some additional parameters for model inference.
# Set up the prompt template
template = """
You are an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the user's question
Question: {question}\n\nAnswer: Let's think step by step."""
prompt = PromptTemplate(template=template, input_variables=["question"])
llm_chain = LLMChain(prompt=prompt, llm=llm)
Here, we define a prompt template for our AI assistant and create an instance of the PromptTemplate class. The template defines the structure of the conversation, with {question} as a placeholder for user input. The LLMChain class integrates the language model and the prompt for easier conversation management.
# Create the Streamlit app
def main():
# Initialize the app
# Process the user input
# Generate and display the assistant's response
if __name__ == "__main__":
main()
In the main function, we build the Streamlit application. We set up the chat interface, process user input, and use our language model to generate responses.
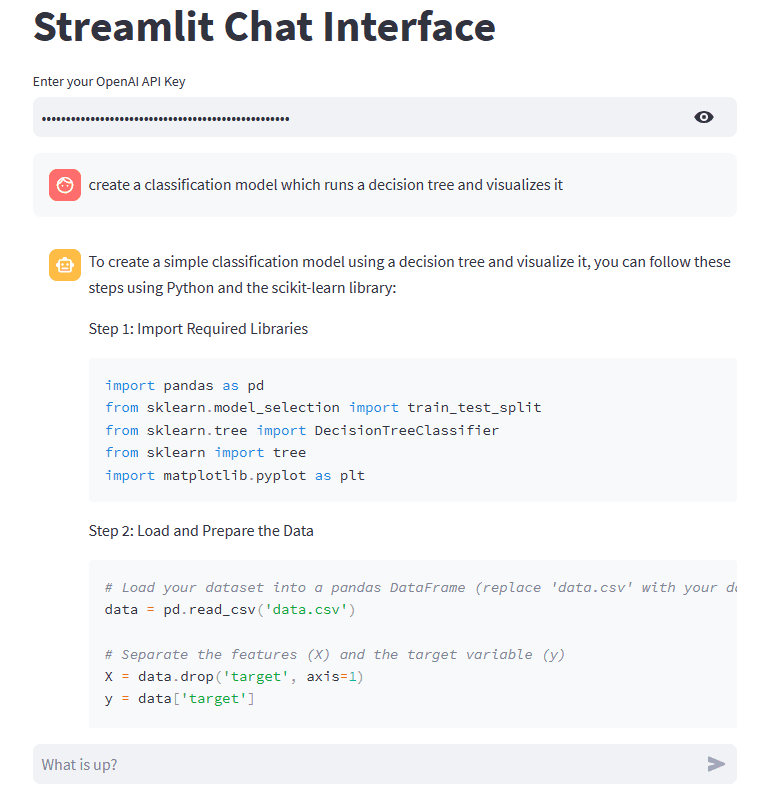
The final result is an interactive, user-friendly AI assistant that can answer a wide range of questions with detailed, insightful responses.
Feel free to visit the full code on my GitHub repository. You can also connect with me on LinkedIn and Twitter for more updates and discussions.