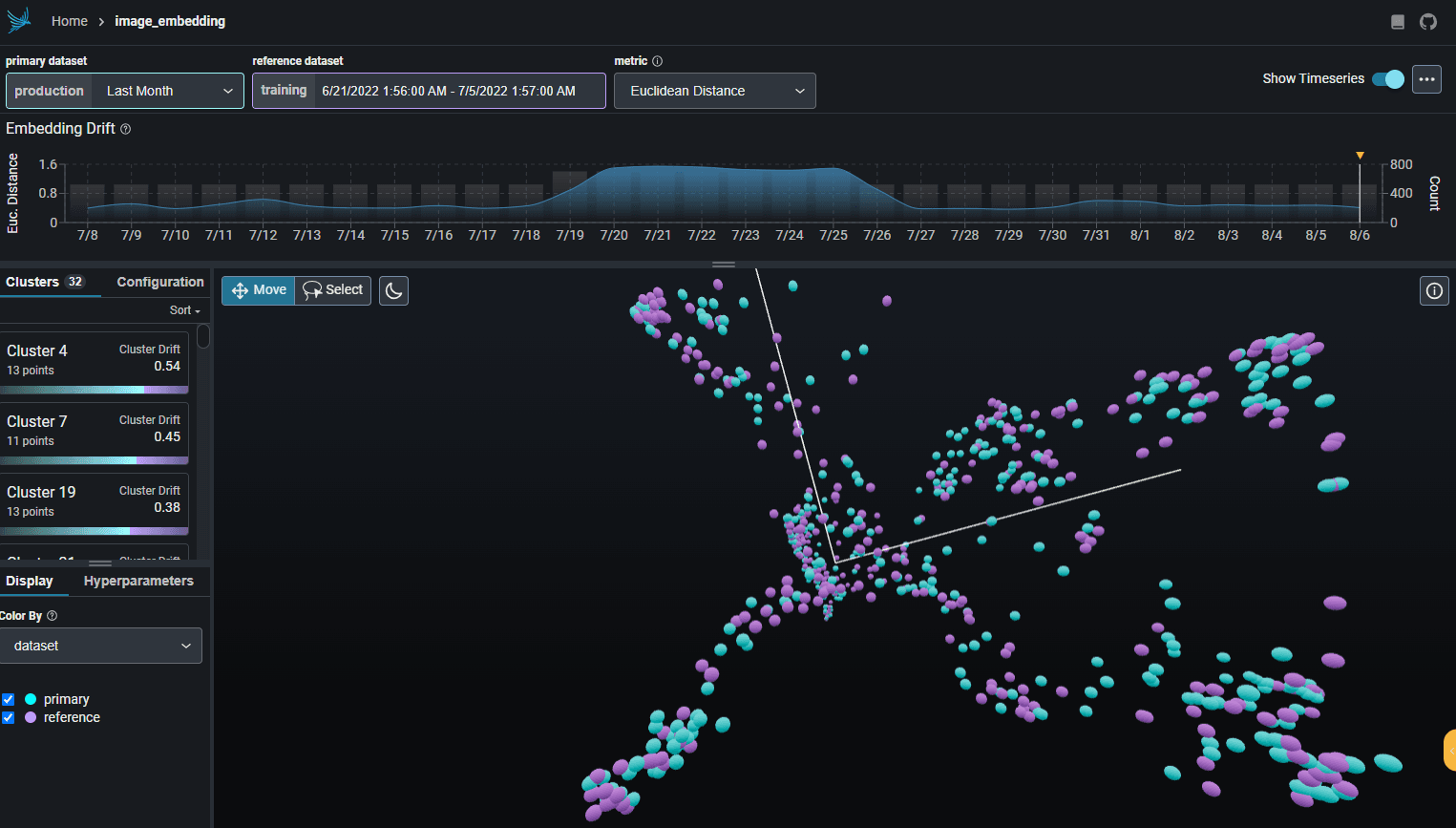
Transformers & CNNs
The intriguing debate surrounding the relationship between Convolutional Neural Networks (CNNs) and Transformers in the context of Natural Language Processing (NLP) offers a fertile ground for academic exploration. While CNNs have been a cornerstone in image recognition, their foray into NLP has also been significant.
On the other hand, Transformers have rapidly ascended to become the architecture of choice for a broad array of NLP tasks. This juxtaposition naturally leads to several compelling questions that warrant a deeper scholarly investigation.
One of the most captivating questions is whether Transformers can be viewed as an evolutionary extension of CNNs. Both architectures employ complex layers of mathematical operations to transform their input, but the mechanisms they use are distinct. CNNs leverage convolutional layers to scan through local regions of the input, effectively capturing spatial hierarchies. Transformers, however, employ attention mechanisms that weigh the importance of different parts of the input sequence, thereby capturing long-range dependencies without being constrained by the input's spatial structure. This begs the question: Are Transformers and CNNs two sides of the same coin, capturing similar computational principles but through different lenses?
Attention mechanisms serve as another intriguing point of intersection between these architectures. While attention is often associated with Transformers, it's worth noting that the concept has been applied in various forms across different neural architectures, including CNNs. In the realm of image processing, spatial attention in CNNs focuses on specific regions of the input.
In contrast, the attention mechanism in Transformers is more generalized, allowing for a dynamic focus on different parts of the input sequence. This raises an interesting question: Are these attention mechanisms fundamentally different, or are they nuanced variations of a foundational concept?
The process of architectural discovery is another area ripe for exploration. The development of these architectures often appears to be a blend of empirical discovery and foundational understanding. For instance, the evolution from CNNs to Transformers suggests that while empirical advancements often propel the field forward, they are usually anchored in a theoretical framework. This duality prompts us to consider whether future architectures will emerge from empirical tinkering, foundational understanding, or a synergy of both.
Lastly, the efficiency of these architectures, particularly in training, cannot be overlooked. Transformers have the edge in allowing for parallelization, significantly accelerating the training process. This efficiency is not just a technical footnote but a critical factor that could influence the trajectory of future neural architectures.
Will computational efficiency overshadow the ability to model complex relationships in data, or will it serve as a catalyst for new architectural innovations?
In sum, the relationship between CNNs and Transformers is far from straightforward. It's a complex tapestry woven from evolutionary advancements, shared computational principles, and practical considerations like efficiency. While it's tempting to view one as a mere extension of the other, such a perspective is likely too reductive.
A nuanced understanding calls for a multi-dimensional investigation that delves into the computational, theoretical, and empirical realms that these architectures inhabit.