Phoenix: A Powerful Tool for MLOps Insights and Model Observability
Phoenix, developed by Arize AI, is a Python library designed to provide MLOps insights at lightning speed with zero-config observability for model drift, performance, and data quality. It is a notebook-first library that leverages embeddings to uncover problematic cohorts of your Language, Computer Vision, NLP, and tabular models.
Key Features
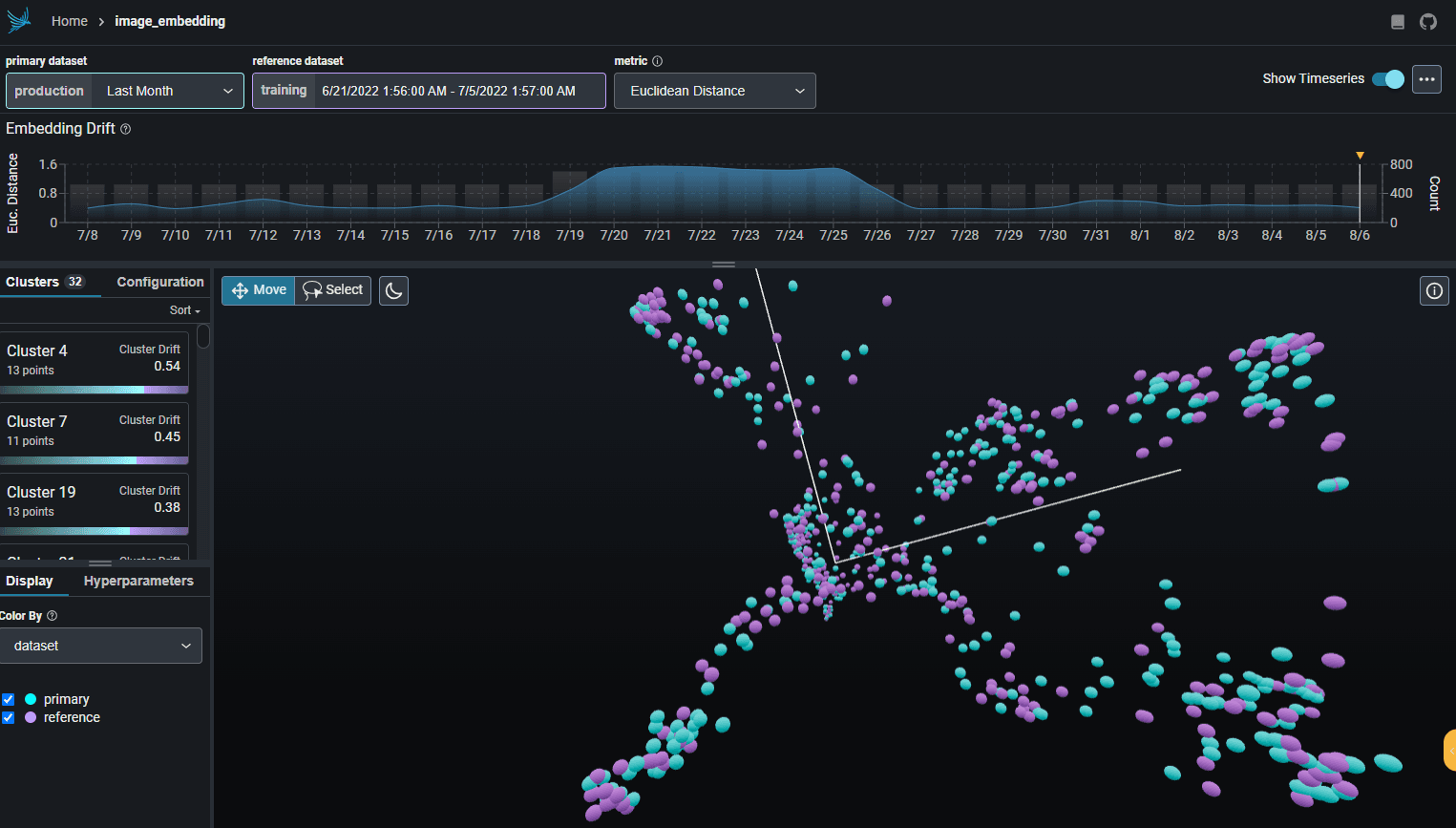
Embedding Drift Analysis: Phoenix allows you to explore UMAP point-clouds at times of high Euclidean distance and identify clusters of drift.
UMAP-based Exploratory Data Analysis: You can color your UMAP point-clouds by your model's dimensions, drift, and performance to identify problematic cohorts.
Cluster-driven Drift and Performance Analysis: Phoenix provides the ability to break apart your data into clusters of high drift or bad performance using HDBSCAN.
Exportable Clusters: You can export your clusters to
parquetfiles or dataframes for further analysis and fine-tuning.
A Data Scientist's Perspective
As a data scientist, the ability to observe and understand the behaviour of machine learning models is crucial. Phoenix offers a streamlined and intuitive approach to model observability, making it easier to identify and address issues that may affect model performance.
The library's focus on notebook-first development aligns well with the workflows of many data scientists, allowing for seamless integration into existing processes. The use of embeddings for identifying problematic cohorts is a powerful feature, enabling more granular insights into model performance across different segments of data.
The ability to export clusters for further analysis is particularly useful, as it allows for deeper exploration and understanding of areas where the model may be underperforming or experiencing drift. This can inform model refinement and retraining efforts, ultimately leading to improved model performance.
Quickstart Guide
To get started with Phoenix, you can install it using pip:
pip install arize-phoenix
After installation, you can import the necessary libraries and load your datasets into pandas DataFrames. Phoenix requires you to define schemas that tell it which columns of your DataFrames correspond to features, predictions, actuals (i.e., ground truth), embeddings, etc.
Here is an example of how you might set up and use Phoenix:
import pandas as pd
import phoenix as px
# Load your datasets
train_df = pd.read_csv('train.csv')
prod_df = pd.read_csv('prod.csv')
# Define your schemas
train_schema = px.Schema(
features=['feature1', 'feature2', 'feature3'],
prediction='prediction',
actual='actual',
embeddings=['emb1', 'emb2', 'emb3']
)
prod_schema = px.Schema(
features=['feature1', 'feature2', 'feature3'],
prediction='prediction',
actual='actual',
embeddings=['emb1', 'emb2', 'emb3']
)
# Create your datasets
train_ds = px.Dataset(df=train_df, schema=train_schema)
prod_ds = px.Dataset(df=prod_df, schema=prod_schema)
# Launch the Phoenix app
session = px.launch_app(prod_ds, train_ds)
# View the Phoenix UI in your notebook
session.view()
# Don't forget to close the app when you're done
px.close_app()
Phoenix is a powerful tool for any data scientist or ML engineer looking to gain deeper insights into their models and improve their performance.