Optimizing Large Language Model Inference with Continuous Batching
In the rapidly evolving field of machine learning, large language models (LLMs) have emerged as critical component for a variety of applications. These models, with their ability to generate human-like text, have revolutionized tasks like text completion, translation, and even creative writing. However, the deployment of these models in real-world applications is not without challenges. The large GPU memory footprint and compute cost of LLMs often dominate the compute cost for most applications, making their efficient use a key concern.
The Intricacies of LLM Inference
LLM inference is an iterative process where a sequence of completion tokens is produced. The process begins with an initial prompt and continues until a stop token is produced or a maximum sequence length is reached. For instance, if you prompt with a sentence "What is the capital of Karnataka: ", it would take nine forward pass iterations to get back the full response of ["B", "e", "n", "g", "a", "l", "u", "r", "u"].
However, there are some lesser-known facts about LLM inference:
The initial ingestion of the prompt takes about as much time as the generation of each subsequent token. This is due to the prefill phase that pre-computes some inputs of the attention mechanism that remain constant over the lifetime of the generation.
LLM inference is memory-IO bound, not compute bound. This means that LLM inference throughput is largely determined by how large a batch you can fit into high-bandwidth GPU memory.
The amount of GPU memory consumed scales with the base model size + the length of the token sequence. For a 13B parameter model, nearly 1MB of state is consumed for each token in a sequence.
Continuous Batching: A Game Changer
Continuous batching, also known as dynamic batching or batching with iteration-level scheduling, is a memory optimization technique that does not require modification of the model. It addresses many of the inefficiencies of request-based dynamic batching. In essence, continuous batching allows for the processing of requests as soon as they arrive, rather than waiting for a full batch to accumulate. This leads to better utilization of GPU memory and higher throughput.
Benchmark results show that users can achieve up to 23x LLM inference throughput while reducing p50 latency by leveraging continuous batching and continuous batching-specific memory optimizations. These results highlight the potential of continuous batching as a powerful tool for optimizing LLM inference.
The Future of LLM Inference
The advent of continuous batching marks a significant advancement in the field of LLM inference. It not only improves throughput but also reduces latency, making it a valuable technique for serving LLM models cost-effectively. As we continue to push the boundaries of what's possible with LLMs, techniques like continuous batching will play a crucial role in ensuring that these models can be deployed efficiently and effectively.
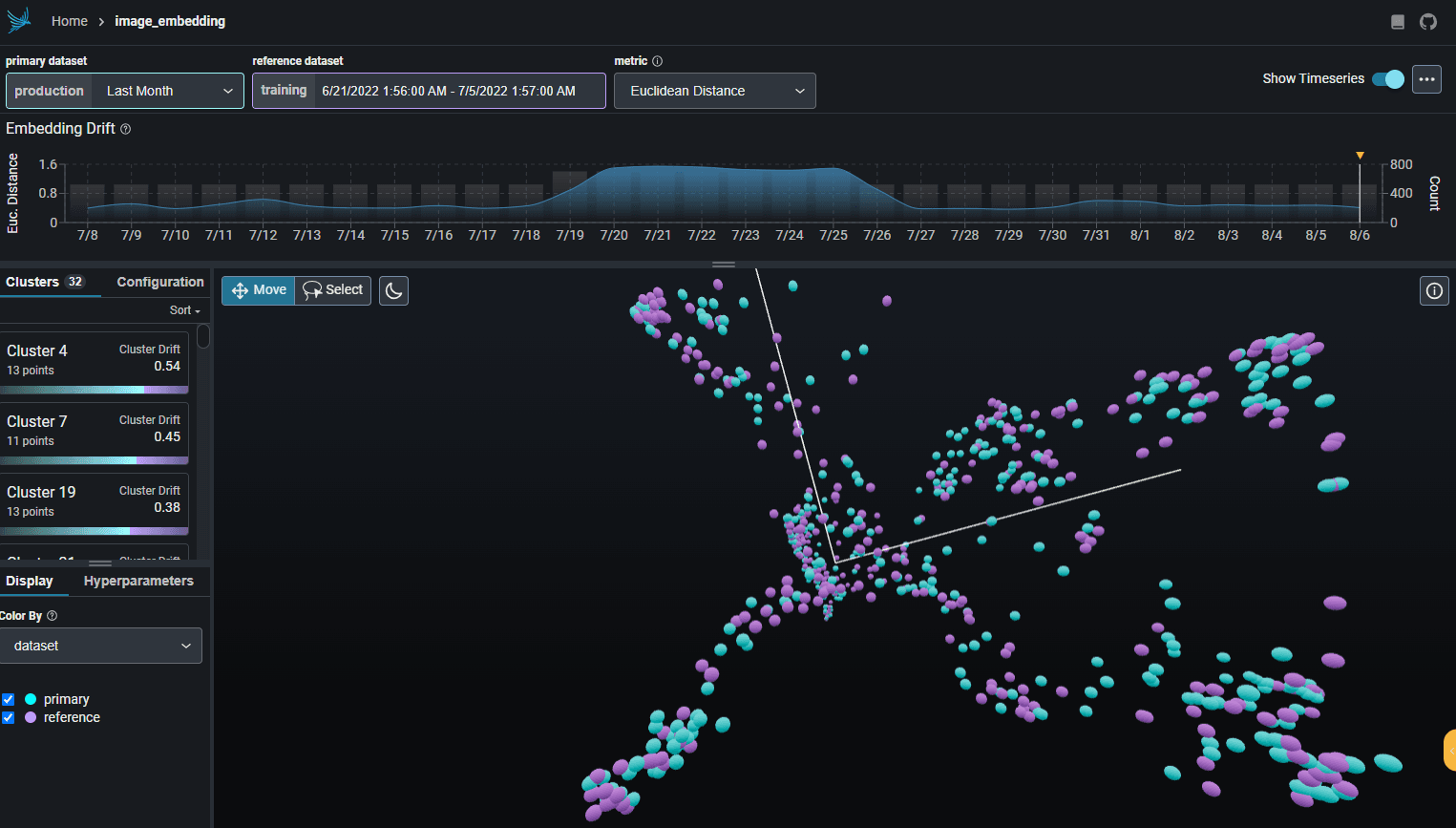
Visualizing the Concepts
To further enhance our understanding, let's visualize some of the concepts discussed in this blog post.
LLM Inference Process This diagram illustrates the iterative process of LLM inference, starting from the initial ingestion of the prompt to the generation of completion tokens.
Memory Consumption in LLM Inference This diagram depicts how the amount of GPU memory consumed scales with the base model size and the length of the token sequence.
Continuous Batching in LLM Inference This diagram shows how continuous batching works in LLM inference, highlighting how it improves memory efficiency and throughput.
These diagrams provide a visual understanding of the concepts and processes discussed in the blog post. They help to illustrate the importance and benefits of continuous batching in LLM inference.
As we continue to explore and innovate in the field of machine learning, techniques like continuous batching will be instrumental in driving forward the efficiency and effectiveness of large language models.
More reading: https://www.anyscale.com/blog/continuous-batching-llm-inference